Data Analyse og Forretning
Dine data er guld værd
 Alex Scheel Meyer
Alex Scheel Meyer
Vi vil alle gerne tage gode beslutninger og det er svært at forestille sig succes i forretning uden gode beslutninger.
Selvom nogle godt kan lide at "skyde fra hoften" når de tager beslutninger, så vil de fleste gerne undersøge tingene først for at sikre sig at de har det rigtige beslutningsgrundlag. Data analyse er grundlæggende bare det at undersøge tingene for at skabe et godt grundlag for at tage gode beslutninger.
Med den hastighed data bliver skabt i dag er man dog ofte motiveret til at analysere data alene fordi der kan være guldkorn i de data som man ikke vil gå glip af. Selv uden at snakke "Big Data", vil mange virksomheder have mere end rigeligt data som der kan analyseres på. Selv små virksomheder har data omkring salg og pengestrømme, det er jo hvad et regnskab er. Selv små virksomheder vil gerne føle sig sikre på at deres ide til et produkt kan overleve i det valgte marked, det er jo hvad en forretningsplan er. Selv små virksomheder har i dag brug for en fornuftig strategi i forhold til de mange potentielle kunder som findes på sociale medier.
Når virksomheder bliver større, bliver behovet for data analyse også større. Machine learning teknikker kan hjælpe virksomheder med at analysere data automatisk så det bliver nemmere og hurtigere at finde guldkornene.
En ofte brugt teknik er t-SNE (t-distributed Stochastic Neighbor Embedding) som er en teknik der kan tage elementer med mange parametre tilknyttet og vise det som en 2-dimensionel graf. Lidt som når et kamera kan tage et fladt billede af vores 3-dimensionelle verden, bare hvor t-SNE kan håndtere mange flere dimensioner end 3. Herunder vises en t-SNE graf for produkt-data med forskellige klasser og man kan se hvordan nogle produkter skiller sig fint ud og er selvstændige (5 og 6), mens andre i højere grad overlapper (2, 3 og 4).

Sådan en visualisering vil kunne fungere som indgangsvinkel til nærmere analyse af de enkelte punkter, f.eks. for at blive klogere på hvorfor der måske er mere overlap end man forventer.
Hvis den samme visualisering blev brugt til data omkring potentielle kunder, så ville man måske være mere interesseret i grupper der skiller sig meget ud, med tanke på at tilbyde de kunder et produkt som appellerer specifikt til dem (hvis ikke det findes i forvejen).
Herunder er et andet eksempel. Denne gang involverer det ikke machine learning men er et udtræk og en visualisering af data som allerede findes i systemet. Det her projekt involverer software udvikling med Git versionsstyring. Hver cirkel i visualiseringen er en software opgave som har en tilhørende "branch" i versionsstyring. Ved at have 3 forskellige akser at vise data på kan man visualisere det på flere forskellige måder og man kan f.eks. tænke sig at man vil være særligt interesseret i at finde ud af hvorfor nogle funktionaliteter lever i flere hundrede dage eller har rigtig mange kommentarer.
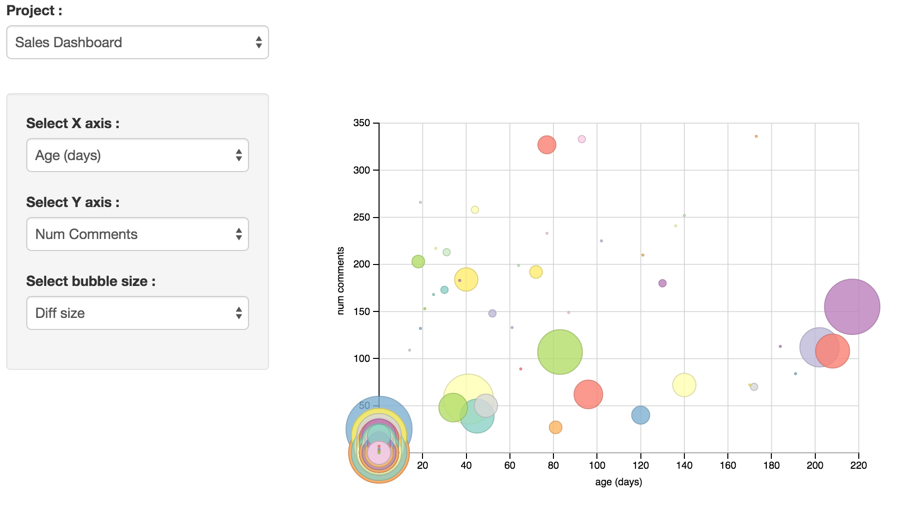
Selvom det ikke kræver machine learning at lave sådan en visualisering, så kan man, hvis man har mange opgaver og projekter, vælge at bruge machine learning til at estimere for hver opgave hvor stor risikoen er for at den lever i mere end 50 dage f.eks. Det betyder at man forhåbentlig kan tage hånd om funktionaliteter der viser sig vanskelige tidligere i forløbet og eventuelt tage beslutning om at droppe det eller ændre på kravene. I software er det ofte en kerneopgave at sikre sig at mængden af arbejde som bruges på funktionalitet står mål med værdien for virksomheden.
En opgave som det også er meget populært at bruge machine learning til, er "outlier detection" det vil sige detektering af unormale data.
Det bruges i både forsikringsbranchen og generelt når der håndteres finansielle transaktioner. Man bruger et machine learning program til simpelthen at finde eksempler som der skal kigges nærmere på af et menneske for at undersøge om der er tale om svindel. Med de mange krav der stilles i dag til kontrol af finansielle transaktioner for at undgå hvidvaskning og finansiering af terrorisme, så er det næsten den eneste måde det kan lade sig gøre på, da der er så mange transaktioner at medmindre man på denne måde nemt kan filtrere dem, så ville det være alt for bekosteligt at et menneske skal kigge dem alle sammen igennem.
Et andet område hvor outlier detection bruges er i forbindelse med kvalitetskontrol. Typisk har man et kamera eller en anden slags sensor som for hvert produceret emne laver nogle målinger. Man bruger så outlier detection til automatisk at signalere når der er emner som potentielt ikke overholder kvalitetskravene. Igen kan der spares resourcer ved at bruge machine learning som et filter, så arbejdsopgaven for mennesker bliver mindre.
I dag er machine learning teknikker til data analyse ved at infiltrere alle dele af virksomheders processer. For nogle af de største firmaer er det endda kernen i deres forretning. Eksempler er Google og Facebook som gør brug af machine learning til at lave en "parring" mellem forskellige typer indhold. Måden det fungerer på er at man træner algoritmen til at lære at vurdere hvor godt 2 måske vidt forskellige elementer passer sammen. For Google og Facebook tager de informationer om deres brugere og parrer det med informationer om reklamer - på den måde kan de optimere så det er de mest relevante reklamer som der vises. Et andet eksempel er Amazon der parrer produkter sammen som ofte er købt af den samme bruger - her kan de så bruge det til at foreslå andre produkter du kunne være interesseret i at købe, eller måske direkte lave et godt tilbud kun til dig baseret på dine tidligere køb.
Denne her udvikling hvor den traditionelle data analyse udført af folk som er eksperter på hver deres område bliver udbygget og i nogle tilfælde erstattet af nye teknikker som bruger machine learning, den vil fortsætte længe endnu. Det vil ske gradvist, men det vil være sværere og sværere at gøre sig i konkurrencen med virksomheder der bruger disse teknikker.
Så hvis du ikke allerede er klar over hvad disse teknikker kan gøre for netop din forretning, så er det en god ide at undersøge mulighederne nærmere.